SARSA
SARSA (State-Action-Reward-State-Action) is an on-policy reinforcement learning algorithm that learns by updating its value estimates based on the actions it actually takes. The name comes from the sequence of information it uses: it observes the current state (S), takes an action (A), receives a reward (R), moves to a new state (S), and then selects the next action (A) before updating its knowledge. Unlike Q-learning which always assumes optimal future actions, SARSA updates its estimates based on the action it will actually take next, including any exploratory random actions.
How SARSA Works
The algorithm maintains a Q-table that stores value estimates for every state-action pair. When the agent takes an action and observes the result, it updates the Q-value using the formula:
Q(s,a) ← Q(s,a) + α[r + γ·Q(s',a') - Q(s,a)],
where α is the learning rate, γ is the discount factor, and crucially, a' is the actual next action the agent will take (chosen by its current policy). This means SARSA learns the value of the policy it's actually following, including the exploration strategy, making it an on-policy learner that's more conservative and realistic about its capabilities. This is in contrast to the off-policy nature of Q-Learning which takes best possible next action regardless of what action the agent will actually take.
When to Use SARSA
SARSA is particularly valuable in real-world applications where safety during learning matters, such as robotics, autonomous vehicles, or healthcare, because it accounts for the fact that the agent might take exploratory actions that could be risky. While this makes SARSA more conservative and potentially slower to converge to the optimal policy compared to Q-learning, it learns policies that are safer during training because it doesn't assume perfect future behavior. It's the preferred choice when you can't afford catastrophic mistakes during the learning process and need the agent to be cautious about risky states even during exploration.
Example Calculations
To illustrate how SARSA works lets assume that an agent lives a grid world shown below:
+------+------+------+------+------+
| | | | | |
+------+------+------+------+------+
| | | | | |
+------+------+------+------+------+
| A | X | X | X | G |
+------+------+------+------+------+where 'A' is the agent (starting point), 'G' is the goal. 'X' represents a cliff. The objective of the agent is to learn how to avoid the cliff and to reach the goal. The reward for the reaching the goal is 10 and for stepping onto the cliff is -0.1. The agent will start again if it steps onto the cliff. The agent will remain at the same position if it moves againts the boundary of the grid world. The agent will also receive a reward of -1 for everystep taken. This is to encourage the agent to take the shortest route possible. The agent can only move in 4 directions (actions): Up, Right, Down Left. Action is selected based on the Epsilon-greedy (ε-greedy) policy i.e. to choose the best-known action most of the time with probability 1−ε (exploitation) while occasionally selecting a random action with probability ε (exploration) to discover potentially better options.
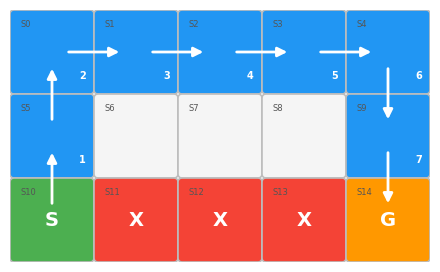
Each grid represents a state as shown below:
+------+------+------+------+------+
| S0 | S1 | S2 | S3 | S4 |
+------+------+------+------+------+
| S5 | S6 | S7 | S8 | S9 |
+------+------+------+------+------+
| S10 | S11 | S12 | S13 | S14 |
+------+------+------+------+------+Let's go through a training episode of 10 steps starting at state S10:
alpha = 0.1 # learning rate
gamma = 0.95 # discount factor
starting epsilon = 1.0 # exploration probability
epsilon decay: 0.995 # epsilon is multiplied by this amount after each training episode
Episode #1: Step #1
-------------------
Current state: S10
Action taken: Up (explore)
Reward received: -0.1
Next state: S5
Next action selected: Down (explore)
Current Q-table of states S5 and S10
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S5 | +0.000 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
| S10 | +0.000 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Q(S10, Up) = 0.00 + 0.1(0 + 0.95(0.00 - (0.00))) = -0.01
Updated Q-table of state 10
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S10 | -0.010 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Episode #1: Step #2
-------------------
Current state: S5
Action taken: Down (from Step #1 next action selected)
Reward received: -0.1
Next state: S10
Next action selected: Up (explore)
Current Q-table of states S5 and S10
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S5 | +0.000 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
| S10 | -0.010 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Q(S5, Down) = 0.00 + 0.1(0 + 0.95(-0.01 - (0.00))) = -0.01
Updated Q-table of state 5
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S5 | +0.000 | -0.011 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Episode #1: Step #3
-------------------
Current state: S10
Action taken: Up (from Step #2 next action selected)
Reward received: -0.1
Next state: S5
Next action selected: Up (explore)
Current Q-table of states S5 and S10
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S5 | +0.000 | -0.011 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
| S10 | -0.010 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Q(S10, Up) = -0.01 + 0.1(0 + 0.95(0.00 - (-0.01))) = -0.02
Updated Q-table of state 10
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S10 | -0.019 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Episode #1: Step #4
-------------------
Current state: S5
Action taken: Up (from Step #3 next action selected)
Reward received: -0.1
Next state: S0
Next action selected: Up (explore)
Current Q-table of states S0 and S5
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | +0.000 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
| S5 | +0.000 | -0.011 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Q(S5, Up) = 0.00 + 0.1(0 + 0.95(0.00 - (0.00))) = -0.01
Updated Q-table of state 5
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S5 | -0.010 | -0.011 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Episode #1: Step #5
-------------------
Current state: S0
Action taken: Up (from Step #4 next action selected)
Reward received: -0.1
Next state: S0
Next action selected: Down (explore)
Current Q-table of state S0
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | +0.000 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Q(S0, Up) = 0.00 + 0.1(0 + 0.95(0.00 - (0.00))) = -0.01
Updated Q-table of state 0
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | -0.010 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Episode #1: Step #6
-------------------
Current state: S0
Action taken: Down (from Step #5 next action selected)
Reward received: -0.1
Next state: S5
Next action selected: Up (explore)
Current Q-table of states S0 and S5
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | -0.010 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
| S5 | -0.010 | -0.011 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Q(S0, Down) = 0.00 + 0.1(0 + 0.95(-0.01 - (0.00))) = -0.01
Updated Q-table of state 0
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | -0.010 | -0.011 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Episode #1: Step #7
-------------------
Current state: S5
Action taken: Up (from Step #6 next action selected)
Reward received: -0.1
Next state: S0
Next action selected: Right (explore)
Current Q-table of states S0 and S5
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | -0.010 | -0.011 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
| S5 | -0.010 | -0.011 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Q(S5, Up) = -0.01 + 0.1(0 + 0.95(0.00 - (-0.01))) = -0.02
Updated Q-table of state 5
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S5 | -0.019 | -0.011 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Episode #1: Step #8
-------------------
Current state: S0
Action taken: Right (from Step #7 next action selected)
Reward received: -0.1
Next state: S1
Next action selected: Left (explore)
Current Q-table of states S0 and S1
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | -0.010 | -0.011 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
| S1 | +0.000 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Q(S0, Right) = 0.00 + 0.1(0 + 0.95(0.00 - (0.00))) = -0.01
Updated Q-table of state 0
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | -0.010 | -0.011 | +0.000 | -0.010 |
+-----------+----------+----------+----------+----------+
Episode #1: Step #9
-------------------
Current state: S1
Action taken: Left (from Step #8 next action selected)
Reward received: -0.1
Next state: S0
Next action selected: Up (explore)
Current Q-table of states S0 and S1
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | -0.010 | -0.011 | +0.000 | -0.010 |
+-----------+----------+----------+----------+----------+
| S1 | +0.000 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Q(S1, Left) = 0.00 + 0.1(0 + 0.95(-0.01 - (0.00))) = -0.01
Updated Q-table of state 1
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S1 | +0.000 | +0.000 | -0.011 | +0.000 |
+-----------+----------+----------+----------+----------+
Episode #1: Step #10
--------------------
Current state: S0
Action taken: Up (from Step #9 next action selected)
Reward received: -0.1
Next state: S0
Next action selected: Down (explore)
Current Q-table of state S0
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | -0.010 | -0.011 | +0.000 | -0.010 |
+-----------+----------+----------+----------+----------+
Q(S0, Up) = -0.01 + 0.1(0 + 0.95(-0.01 - (-0.01))) = -0.02
Updated Q-table of state 0
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | -0.020 | -0.011 | +0.000 | -0.010 |
+-----------+----------+----------+----------+----------+After 10 steps the updated Q-table is shown below. Best action is based on the maximum value in a row; if values are tied, best action is selected randomly.
+-----------+----------+----------+----------+----------+--------+
| State | Up | Down | Left | Right | Best |
+-----------+----------+----------+----------+----------+--------+
| S0 | -0.020 | -0.011 | +0.000 | -0.010 | Left |
+-----------+----------+----------+----------+----------+--------+
| S1 | +0.000 | +0.000 | -0.011 | +0.000 | Down |
+-----------+----------+----------+----------+----------+--------+
| S2 | +0.000 | +0.000 | +0.000 | +0.000 | Left |
+-----------+----------+----------+----------+----------+--------+
| S3 | +0.000 | +0.000 | +0.000 | +0.000 | Down |
+-----------+----------+----------+----------+----------+--------+
| S4 | +0.000 | +0.000 | +0.000 | +0.000 | Down |
+-----------+----------+----------+----------+----------+--------+
| S5 | -0.019 | -0.011 | +0.000 | +0.000 | Right |
+-----------+----------+----------+----------+----------+--------+
| S6 | +0.000 | +0.000 | +0.000 | +0.000 | Up |
+-----------+----------+----------+----------+----------+--------+
| S7 | +0.000 | +0.000 | +0.000 | +0.000 | Up |
+-----------+----------+----------+----------+----------+--------+
| S8 | +0.000 | +0.000 | +0.000 | +0.000 | Right |
+-----------+----------+----------+----------+----------+--------+
| S9 | +0.000 | +0.000 | +0.000 | +0.000 | Up |
+-----------+----------+----------+----------+----------+--------+
| S10 | -0.019 | +0.000 | +0.000 | +0.000 | Left |
+-----------+----------+----------+----------+----------+--------+
| S11 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+
| S12 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+
| S13 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+
| S14 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+Let's take a look at the training for Episode #500. Training for Episode #500 terminates at Step #8 when the agent reached the goal. Epsilon value at the beginning of Episode #500 is 0.082 (1.0x0.995499)
Episode #500: Step #1
---------------------
Current state: S10
Action taken: Up (exploit)
Reward received: -0.1
Next state: S5
Next action selected: Up (exploit)
Current Q-table of states S5 and S10
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S5 | +4.948 | +0.136 | +1.547 | +2.154 |
+-----------+----------+----------+----------+----------+
| S10 | +4.538 | -0.211 | +1.120 | -9.997 |
+-----------+----------+----------+----------+----------+
Q(S10, Up) = 4.54 + 0.1(0 + 0.95(4.95 - (4.54))) = 4.54
Updated Q-table of state 10
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S10 | +4.544 | -0.211 | +1.120 | -9.997 |
+-----------+----------+----------+----------+----------+
Episode #500: Step #2
---------------------
Current state: S5
Action taken: Up (from Step #1 next action selected)
Reward received: -0.1
Next state: S0
Next action selected: Right (exploit)
Current Q-table of states S0 and S5
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | +2.927 | +1.997 | +3.055 | +6.338 |
+-----------+----------+----------+----------+----------+
| S5 | +4.948 | +0.136 | +1.547 | +2.154 |
+-----------+----------+----------+----------+----------+
Q(S5, Up) = 4.95 + 0.1(0 + 0.95(6.34 - (4.95))) = 5.05
Updated Q-table of state 5
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S5 | +5.045 | +0.136 | +1.547 | +2.154 |
+-----------+----------+----------+----------+----------+
Episode #500: Step #3
---------------------
Current state: S0
Action taken: Right (from Step #2 next action selected)
Reward received: -0.1
Next state: S1
Next action selected: Right (exploit)
Current Q-table of states S0 and S1
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | +2.927 | +1.997 | +3.055 | +6.338 |
+-----------+----------+----------+----------+----------+
| S1 | +3.124 | +1.542 | +2.610 | +6.937 |
+-----------+----------+----------+----------+----------+
Q(S0, Right) = 6.34 + 0.1(0 + 0.95(6.94 - (6.34))) = 6.35
Updated Q-table of state 0
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S0 | +2.927 | +1.997 | +3.055 | +6.353 |
+-----------+----------+----------+----------+----------+
Episode #500: Step #4
---------------------
Current state: S1
Action taken: Right (from Step #3 next action selected)
Reward received: -0.1
Next state: S2
Next action selected: Right (exploit)
Current Q-table of states S1 and S2
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S1 | +3.124 | +1.542 | +2.610 | +6.937 |
+-----------+----------+----------+----------+----------+
| S2 | +3.728 | +1.553 | +3.892 | +7.867 |
+-----------+----------+----------+----------+----------+
Q(S1, Right) = 6.94 + 0.1(0 + 0.95(7.87 - (6.94))) = 6.98
Updated Q-table of state 1
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S1 | +3.124 | +1.542 | +2.610 | +6.981 |
+-----------+----------+----------+----------+----------+
Episode #500: Step #5
---------------------
Current state: S2
Action taken: Right (from Step #4 next action selected)
Reward received: -0.1
Next state: S3
Next action selected: Right (exploit)
Current Q-table of states S2 and S3
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S2 | +3.728 | +1.553 | +3.892 | +7.867 |
+-----------+----------+----------+----------+----------+
| S3 | +6.368 | +5.485 | +4.368 | +8.652 |
+-----------+----------+----------+----------+----------+
Q(S2, Right) = 7.87 + 0.1(0 + 0.95(8.65 - (7.87))) = 7.89
Updated Q-table of state 2
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S2 | +3.728 | +1.553 | +3.892 | +7.892 |
+-----------+----------+----------+----------+----------+
Episode #500: Step #6
---------------------
Current state: S3
Action taken: Right (from Step #5 next action selected)
Reward received: -0.1
Next state: S4
Next action selected: Down (exploit)
Current Q-table of states S3 and S4
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S3 | +6.368 | +5.485 | +4.368 | +8.652 |
+-----------+----------+----------+----------+----------+
| S4 | +6.475 | +9.230 | +4.483 | +6.839 |
+-----------+----------+----------+----------+----------+
Q(S3, Right) = 8.65 + 0.1(0 + 0.95(9.23 - (8.65))) = 8.65
Updated Q-table of state 3
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S3 | +6.368 | +5.485 | +4.368 | +8.654 |
+-----------+----------+----------+----------+----------+
Episode #500: Step #7
---------------------
Current state: S4
Action taken: Down (from Step #6 next action selected)
Reward received: -0.1
Next state: S9
Next action selected: Down (exploit)
Current Q-table of states S4 and S9
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S4 | +6.475 | +9.230 | +4.483 | +6.839 |
+-----------+----------+----------+----------+----------+
| S9 | +7.684 | +10.000 | +5.190 | +7.309 |
+-----------+----------+----------+----------+----------+
Q(S4, Down) = 9.23 + 0.1(0 + 0.95(10.00 - (9.23))) = 9.25
Updated Q-table of state 4
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S4 | +6.475 | +9.247 | +4.483 | +6.839 |
+-----------+----------+----------+----------+----------+
Episode #500: Step #8
---------------------
Current state: S9
Action taken: Down (from Step #7 next action selected)
Reward received: 10.0
Next state: S14
Next action selected: Left (explore)
Current Q-table of states S9 and S14
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S9 | +7.684 | +10.000 | +5.190 | +7.309 |
+-----------+----------+----------+----------+----------+
| S14 | +0.000 | +0.000 | +0.000 | +0.000 |
+-----------+----------+----------+----------+----------+
Q(S9, Down) = 10.00 + 0.1(10 + 0.95(0.00 - (10.00))) = 10.00
Updated Q-table of state 9
+-----------+----------+----------+----------+----------+
| State | Up | Down | Left | Right |
+-----------+----------+----------+----------+----------+
| S9 | +7.684 | +10.000 | +5.190 | +7.309 |
+-----------+----------+----------+----------+----------+After 8 steps of Episode #500 the updated Q-table is shown below:
+-----------+----------+----------+----------+----------+--------+
| State | Up | Down | Left | Right | Best |
+-----------+----------+----------+----------+----------+--------+
| S0 | +2.824 | +3.117 | +2.935 | +6.413 | Right |
+-----------+----------+----------+----------+----------+--------+
| S1 | +2.790 | +1.633 | +3.167 | +6.895 | Right |
+-----------+----------+----------+----------+----------+--------+
| S2 | +4.985 | +1.859 | +4.198 | +7.932 | Right |
+-----------+----------+----------+----------+----------+--------+
| S3 | +6.248 | +3.712 | +4.207 | +8.652 | Right |
+-----------+----------+----------+----------+----------+--------+
| S4 | +6.405 | +9.308 | +4.694 | +7.514 | Down |
+-----------+----------+----------+----------+----------+--------+
| S5 | +5.344 | +0.658 | +2.203 | +2.396 | Up |
+-----------+----------+----------+----------+----------+--------+
| S6 | +4.883 | -8.784 | -0.130 | -0.074 | Up |
+-----------+----------+----------+----------+----------+--------+
| S7 | +4.147 | -7.176 | -0.630 | -1.135 | Up |
+-----------+----------+----------+----------+----------+--------+
| S8 | +1.369 | -7.712 | -1.128 | +7.915 | Right |
+-----------+----------+----------+----------+----------+--------+
| S9 | +7.661 | +10.000 | +3.758 | +6.918 | Down |
+-----------+----------+----------+----------+----------+--------+
| S10 | +4.716 | -0.639 | +2.283 | -9.998 | Up |
+-----------+----------+----------+----------+----------+--------+
| S11 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+
| S12 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+
| S13 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+
| S14 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+If we run the training for 2500 episodes, the final updated Q-table is shown below.
+-----------+----------+----------+----------+----------+--------+
| State | Up | Down | Left | Right | Best |
+-----------+----------+----------+----------+----------+--------+
| S0 | +2.824 | +3.117 | +2.935 | +6.413 | Right |
+-----------+----------+----------+----------+----------+--------+
| S1 | +2.790 | +1.633 | +3.167 | +6.895 | Right |
+-----------+----------+----------+----------+----------+--------+
| S2 | +4.985 | +1.859 | +4.198 | +7.932 | Right |
+-----------+----------+----------+----------+----------+--------+
| S3 | +6.248 | +3.712 | +4.207 | +8.652 | Right |
+-----------+----------+----------+----------+----------+--------+
| S4 | +6.405 | +9.308 | +4.694 | +7.514 | Down |
+-----------+----------+----------+----------+----------+--------+
| S5 | +5.344 | +0.658 | +2.203 | +2.396 | Up |
+-----------+----------+----------+----------+----------+--------+
| S6 | +4.883 | -8.784 | -0.130 | -0.074 | Up |
+-----------+----------+----------+----------+----------+--------+
| S7 | +4.147 | -7.176 | -0.630 | -1.135 | Up |
+-----------+----------+----------+----------+----------+--------+
| S8 | +1.369 | -7.712 | -1.128 | +7.915 | Right |
+-----------+----------+----------+----------+----------+--------+
| S9 | +7.661 | +10.000 | +3.758 | +6.918 | Down |
+-----------+----------+----------+----------+----------+--------+
| S10 | +4.716 | -0.639 | +2.283 | -9.998 | Up |
+-----------+----------+----------+----------+----------+--------+
| S11 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+
| S12 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+
| S13 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+
| S14 | +0.000 | +0.000 | +0.000 | +0.000 | - |
+-----------+----------+----------+----------+----------+--------+The optimal path based on the Q-table is illustrated below:
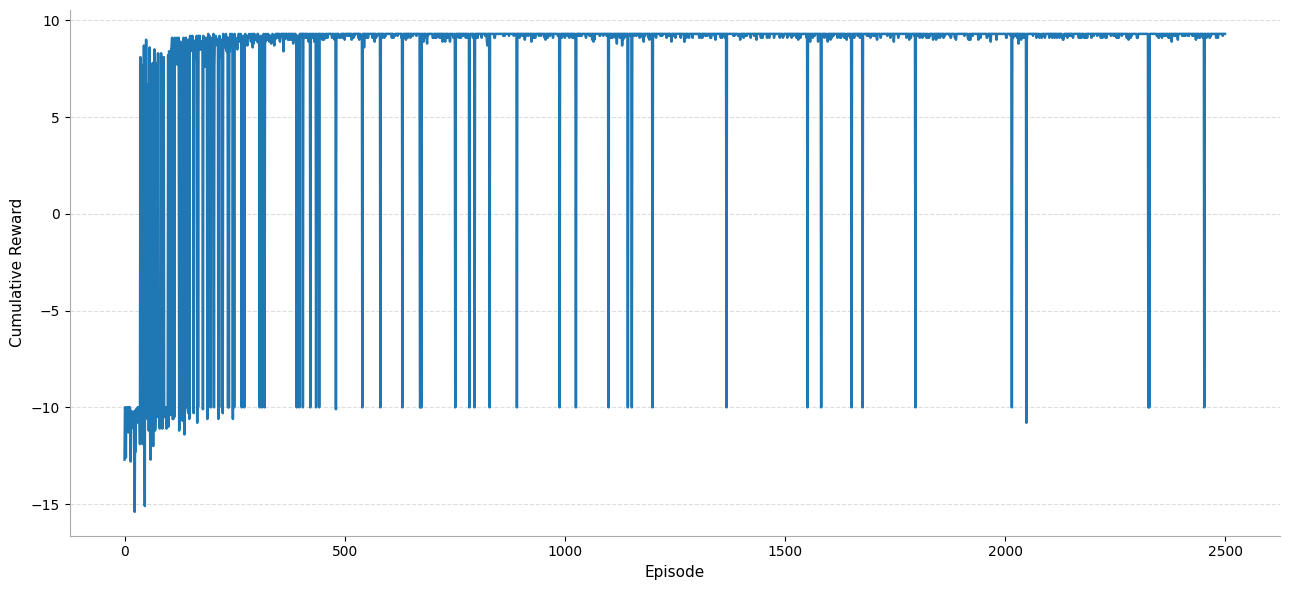
The learning curves for cumulative reward without and with averaging over a window of 50 episodes are shown below respectively.
![Cumulative Reward [window=50]](/_next/static/media/cumulative-reward-50.d133f882.png)